Comment utiliser l’IA de Snowflake Cortex pour les cas d’utilisation géospatiaux
18 juin 2025

Les grands modèles de langage (LLM) redéfinissent la manière dont nous interagissons avec les données, en particulier dans les domaines traditionnellement cloisonnés par des connaissances spécialisées et une complexité technique, comme l’analyse géospatiale. En traduisant le langage naturel en requêtes spatiales structurées, les LLM réduisent considérablement les obstacles techniques à l’extraction d’informations géolocalisées.
Avec des plateformes comme Snowflake Cortex, cette capacité est désormais intégrée directement dans l’entrepôt de données, ce qui permet une expérimentation géospatiale plus rapide et plus accessible que jamais. Ce type de capacités est au cœur de ce que l’on appelle le GeoAI : la combinaison de l’intelligence géospatiale et de l’intelligence artificielle.
Nous pouvons désormais poser des questions spécifiques et le modèle génère une requête SQL spatiale pour récupérer la réponse, comme par exemple :
- « Quelle est la distance entre chaque ligne de ce tableau et un lieu spécifique?
- « Quels sont les clients qui se trouvent à moins de 5 km d’une zone en interruption de service?
- « Pouvez-vous nettoyer cette liste de POI et me dire si les coordonnées correspondent au lieu et à la ville réels?
- « Pouvez-vous normaliser ces adresses au Portugal et inclure le district, la ville et le pays?
Mais si les LLM facilitent l’exploration et le prototypage avec des données spatiales, ils ne remplacent pas la logique géospatiale, la gouvernance ou les performances de production. Sans une intégration minutieuse des fonctions géospatiales (calculs de distance, indexation spatiale, gestion des projections), les LLM peuvent produire des résultats erronés ou simplifiés à l’extrême.
Dans cet article, nous présentons trois cas d’utilisation pratiques qui illustrent la puissance des LLM pour l’analyse géospatiale dans Snowflake :
- Évaluation du risque d’assurance basée sur la proximité des services d’urgence
- Normalisation des adresses pour améliorer la qualité des données d’assurance et la précision du géocodage
- Normalisation des POI pour nettoyer et contextualiser les commodités et attraits dans les listes de biens immobiliers
Cas d’utilisation #1 : GeoAI pour les risques d’assurance – Proximité des services d’urgence
Ce cas d’utilisation montre comment GeoAI et les LLM aident les assureurs à évaluer rapidement le risque immobilier en calculant les distances par rapport aux casernes de pompiers, directement dans Snowflake, sans outils SIG ni requêtes complexes.
Contexte d’affaires
Dans le domaine de l’assurance immobilière, la proximité des services d’urgence, comme les casernes de pompiers, est un facteur déterminant pour la souscription et la tarification. Plus un bien est proche des premiers intervenants, plus le risque perçu est faible – et potentiellement, la prime. Traditionnellement, le calcul de ces relations spatiales nécessite des outils SIG et une expertise en SQL spatial, ce qui crée des frictions entre les utilisateurs professionnels et les informations exploitables.
Ce que fait le LLM
Avec Snowflake Cortex et une petite liste intégrée de coordonnées de casernes de pompiers, nous avons demandé à un LLM de calculer la caserne de pompiers la plus proche pour chaque propriété. Voici un exemple :
Prompt: « Calculez la distance entre chaque propriété assurée et la caserne de pompiers la plus proche dans la ville de Québec. Ne renvoyer que la distance en kilomètres, pas d’autre texte. »
Voici la requête SQL utilisée ainsi que les résultats retournés par le modèle :

Avantages
Cette approche permet aux assureurs d’évaluer rapidement les risques en fonction de la proximité des services d’urgence, sans avoir besoin d’un SIG complet ni d’extraire des données en dehors de l’entrepôt. Toutes les analyses sont effectuées là où se trouvent déjà les données, ce qui garantit de meilleures performances, une meilleure gouvernance et une plus grande évolutivité.
Cas d'utilisation n° 2 : Normalisation des adresses dans le secteur des assurances
Contexte d’affaires
Dans le secteur de l’assurance, des données d’adresses précises et cohérentes sont essentielles pour la souscription, l’évaluation des risques et la gestion des sinistres. Les adresses soumises par les clients se présentent souvent sous des formats variés – avec des codes postaux manquants, des abréviations incohérentes ou des erreurs de formatage – qui peuvent compromettre la précision du géocodage et les calculs de risque.
À l’aide de Snowflake Cortex, nous avons fourni une liste brute d’adresses de clients et demandé au LLM de nettoyer et de normaliser les données :
Prompt:
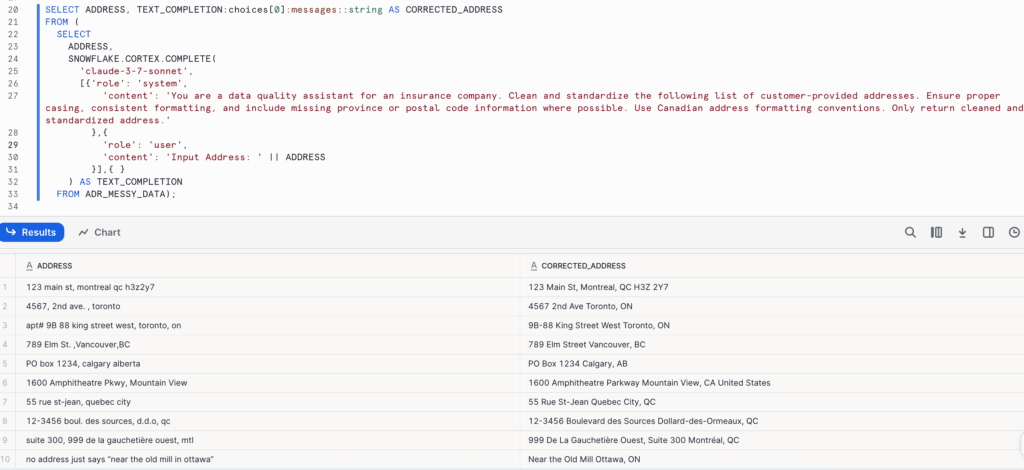
« Nettoyez et normalisez la liste suivante d’adresses fournies par les clients. Veillez à ce que l’orthographe soit correcte, le formatage cohérent et incluez les informations manquantes sur la province ou le code postal lorsque c’est possible. Utilisez les conventions de formatage des adresses canadiennes. Ne renvoyer que les adresses nettoyées et normalisées. »
Voici la requête SQL utilisée et les résultats renvoyés par le modèle :
Avantages
Le LLM a interprété l’intention, corrigé les fautes de frappe, complété les niveaux hiérarchiques de localisation manquants et renvoyé un résultat propre et structuré, le tout dans l’environnement Snowflake. Cela a permis de s’assurer que toutes les adresses étaient conformes à un format cohérent, permettant un géocodage précis et une cartographie des zones à risque.
Cas d’utilisation n°3 : Normalisation des POI dans l’immobilier
Dans les analyses immobilières, les points d’intérêt (POI) – tels que les parcs, les épiceries, les cafés et les écoles – sont essentiels pour évaluer les quartiers et la valeur des propriétés. Mais les données d’annonces soumises par les utilisateurs ou récupérées contiennent souvent des noms de POI mal orthographiés, vagues ou familiers qui ne peuvent pas être géocodés ou agrégés de manière fiable. Ces mentions de POI en texte libre sont incohérentes et difficiles à géocoder de manière fiable.
En appliquant la normalisation de POI alimentée par LLM, les plateformes peuvent :
- Normaliser les noms des points d’intérêt dans les listes (par exemple; « Starbux » → « Starbucks »).
- Résoudre les références vagues ou familières (par exemple; marché alimentaire, le parc près du centre-ville, etc) en utilisant le contexte de la ville et les coordonnées.
- Améliorer la recherche sur carte, l’évaluation des commodités et l’analyse des quartiers.
En utilisant Snowflake Cortex et une liste d’adresses mal orthographiées, nous avons appliqué un prompt au LLM pour nettoyer, normaliser et enrichir automatiquement les données avec un formatage cohérent et des détails géographiques manquants.
Prompt:
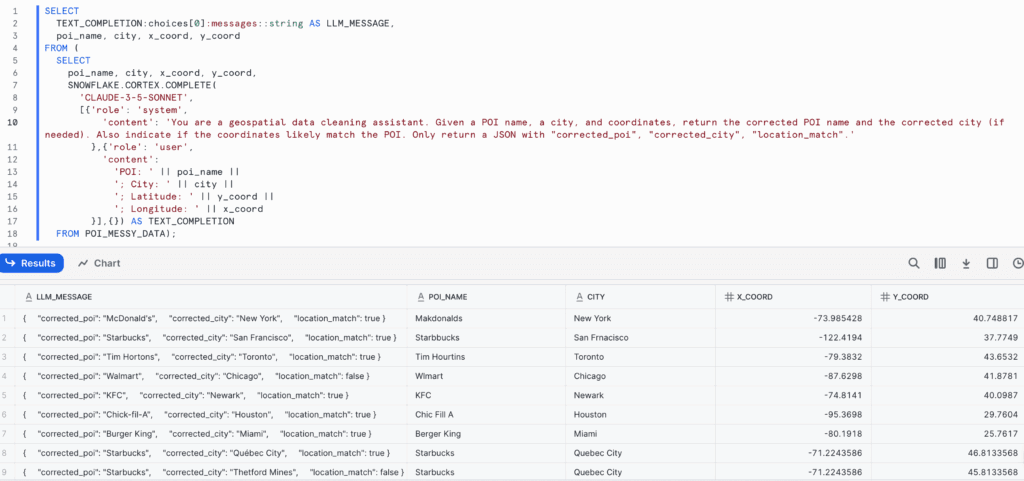
» À partir d’un nom de POI, d’une ville et de coordonnées, renvoyez le nom corrigé du POI et la ville corrigée (le cas échéant). Indiquez également si les coordonnées correspondent au POI. Ne renvoyer qu’un JSON avec « corrected_poi », “corrected_city”, location_match ». «
Voici la requête SQL utilisée ainsi que les résultats renvoyés par le modèle :
Avantages
Le LLM a généré des noms enrichis et cohérents, corrigé les fautes de frappe et clarifié les références locales sur la base d’indices spatiaux. Cette approche accélère la normalisation des adresses en éliminant le traitement manuel ou le besoin d’outils externes. En interprétant l’intention de l’utilisateur et en transformant les données désordonnées en formats cohérents et géocodables, le LLM améliore considérablement la qualité des données d’adresses utilisées dans les analyses.
Limites des LLM pour les utilisations géospatiales
Bien que les grands modèles de langage (LLM) offrent des capacités remarquables pour le prototypage de requêtes spatiales et l’accélération des premières étapes d’analyse, ils ne sont pas encore fiables pour les flux de travail géospatiaux de haut niveau de production sans une intégration SIG appropriée. Plusieurs limitations essentielles doivent être prises en compte :
Résultats imprécis ou simplifiés à l’extrême
Les LLM peuvent mal interpréter les conversions d’unités, mal étiqueter les résultats ou négliger les systèmes de référence des coordonnées. Par exemple, une demande de conversion de distances de miles en kilomètres peut renvoyer les mêmes valeurs numériques avec seulement l’étiquette de l’unité changée, sans appliquer le facteur de conversion correct. Dans les calculs spatiaux, même de petites erreurs numériques peuvent avoir des conséquences commerciales à grande échelle, en particulier dans des domaines tels que l’assurance et la logistique.
Contexte spatial limité
Contrairement aux systèmes SIG qui sont conçus pour respecter les hiérarchies géographiques (par exemple, les quartiers au sein des villes, les villes au sein des provinces), les LLM fonctionnent sans ontologies géographiques intégrées. Ils ne comprennent pas intrinsèquement la différence entre les limites administratives, les projections (par exemple, WGS84 par rapport à UTM) ou les relations topologiques telles que la contiguïté ou le confinement. Ils sont donc enclins à générer des requêtes spatiales syntaxiquement correctes mais sémantiquement erronées.
Problèmes de performance et d’évolutivité
Le code SQL généré par les LLM n’est souvent pas optimisé pour l’échelle. Il peut négliger des pratiques clés de performance spatiale telles que l’indexation spatiale (
ST_CLUSTERKMEANS,ST_CLUSTERDBSCAN, orGEOGRAPHY_INDEXin Snowflake), le filtrage au début des jointures, ou la minimisation du calcul sur de grandes boîtes englobantes. Il peut en résulter des requêtes lentes qui ne s’étendent pas sur des millions de lignes, ce qui entrave l’utilisation en production dans des environnements à haut débit.Absence de validation intégrée
Les LLM n’ont pas la capacité de raisonner sur la validité des résultats qu’ils génèrent. Ils ne savent pas si leur jointure spatiale a retourné les bons résultats, ou si un rayon tampon a été appliqué correctement. C’est donc à un humain d’examiner et de tester manuellement les requêtes, d’où l’importance d’experts géospatiaux tels que Korem.
Optimisation des coûts et des requêtes
Les LLM peuvent générer des requêtes spatiales fonctionnelles, mais ils n’optimisent pas toujours les coûts. Par exemple, demander des distances entre un tableau de propriétés et une liste de casernes de pompiers peut donner lieu à une requête inutilement complexe ou inefficace. Dans Snowflake, une simple fonction commeST_DISTANCEserait plus efficace et beaucoup moins coûteuse.Même des prompts bien écrits peuvent conduire à une utilisation excessive des crédits, donc la validation et l’optimisation des requêtes restent essentielles.
Éléments à retenir
Les LLM peuvent accélérer l’expérimentation, réduire le temps nécessaire pour obtenir de l’information et élargir l’accès géospatial aux non-experts, mais ils ne remplacent pas les systèmes SIG robustes, la connaissance du domaine ou la logique spatiale validée. Lorsqu’elles sont intégrées avec soin dans un environnement gouverné comme Snowflake, elles deviennent un puissant copilote (mais pas un pilote automatique) pour les analyses basées sur la localisation.
Pour les solutions de production, en particulier celles qui impliquent de grands ensembles de données ou qui exigent une grande précision spatiale, le rôle des moteurs géospatiaux reste essentiel.
La voie la plus efficace est une voie hybride : intégrer les LLM là où ils peuvent apporter le plus de valeur ajoutée (comme les interfaces en langage naturel, le prototypage et l’automatisation) tout en continuant à s’appuyer sur les plateformes SIG et les experts géospatiaux pour garantir la précision, l’évolutivité et la fiabilité.
En tant que partenaire Select Tier de Snowflake, Korem peut aider les organisations à exploiter la puissance de cette plateforme en combinant son expertise géospatiale avec les capacités d’IA de Snowflake. Que vous soyez à la recherche d’une géo-analyse avancée, d’une modélisation complexe basée sur des données à grande échelle, ou d’une intégration fluide de l’intelligence de localisation dans vos flux de données, nous pouvons vous aider à avancer plus vite – en toute confiance.
Contactez-nous dès aujourd’hui pour discuter de votre projet.
