The Challenges of Operationalizing AI Models With Real-Time Business Data
March 18, 2020

Even though the AI acronym is on the lips of every data scientist, IT manager and developer hungry for new technologies, the term has its origins around the middle of the last century. After the first reference to AI in the late 1950’s, a couple of years passed before people could grasp what it was really about, and got a taste of what it was.
In the late seventies, we became aware of the notion of artificial intelligence through the well-known Star Wars, Terminator, Robocop, Alien and Blade Runner movies. Above and beyond the blend of science fiction and action, these movies depict visionary scenarios involving AI and its various components. This era coincides with the decreasing cost of AI computing, and its increasing accessibility.
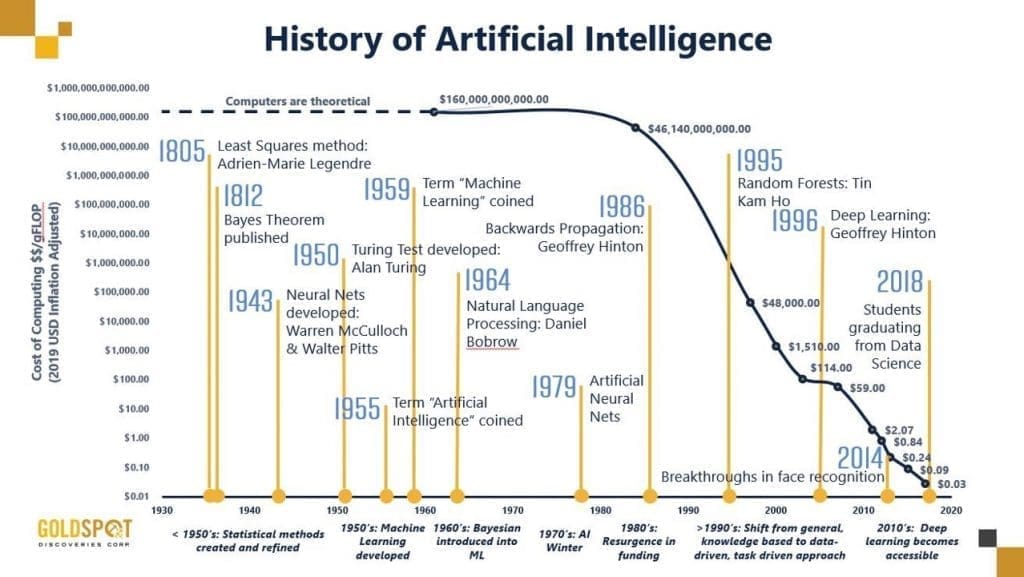
Facial recognition, image processing, wireless communication, the mix between human and machine and the feelings of robots were subtly introduced into our subconsciousness through various media. However, it remained science fiction that we never thought would be accessible even in a far-off future… And now, here we are. The exponential increase of accessibility to AI-related fields came along with the democratization of various topics such as Machine Learning, Data-driven Deep Learning and data science as a whole.
That being said, R2D2, T-2000 and other cybernetic entities with real-time implemented AI algorithms did not become autonomous without the long process of design, development and the automated production stage that we call operationalizing (a more complex task than just deploying), the central piece separating theory and reality. It is a challenge that all organizations and business have, and will continue to face.
Between development and production — the operationalization step
Designing and developing Machine Learning (ML) models is like working in a biological laboratory: you control all inputs and experiment with conditioning parameters while working in a sterile environment, free of contamination by bad data. The access to the required data is ensured whether its cloud-based or on a local database infrastructure. Sometimes you can also proceed in an old-school way, building your own static extracts to avoid unexpected changes and guaranteeing suitable versioning of your data inputs. This framework allows the best possible conditions to build algorithms and perform tests, from model training to inference.
Once you go on the field, outside your development lab to operationalize your AI solution, it’s a whole different story in another world. The area between development analytics and production environment is a no man’s land discrepancy that is sometimes called “Death Valley” by some companies that face this challenge. Overall, five key points can be listed to overcome this barrier in terms of AI operationalization:
1. Data Accessibility
Many corporations and companies have their own IT departments, software and database storing systems. Consequently, business data might not be available, or may not even exist. This aspect opens a Pandora’s box on the subject of how and where business data is stored, on which format, which quantity, and how to get access to these in an automated environment in production.
Nowadays, there is plenty of third-party data that can be used to geo-enrich and feed models to increase their accuracy, from socio-demographics and segmentation data to property, social expenditures, traffic and weather data. In a development environment, some datasets are available through trial or low-cost user-based licenses. However, if the model development version is to be used by private organizations or even open to the public, getting access to modeling third-party data can lead to other challenges, from legal use cases to high costs situations.
2. Data security and governance
3. Data Quality
4. Big Data Processing Capabilities
In the development stage, it is possible to optimize computing power and processing to minimize the execution time, maximize efficiency, and get the best possible IT system. In production, the IT infrastructure can be completely different and not always suitable to run deep learning algorithms connected with Big Data environments. With large amounts of data, even multi-core servers are not enough to retrain a model in a reasonable time frame. Big data and cloud environments need to be leveraged through technologies like Databricks to enable big data APIs mixed with ML algorithms. Therefore, some companies are often stuck with this burden which does not always make any implementation achievable, the need to leverage Big Data and cloud environments is inevitable.
The difference between model training and inference can be huge. Deep Learning techniques involve large data amounts that may lead to pitfalls when computing power is not enough. Once the model is created, the execution does not necessarily require the horsepower installed at the development level. On the other hand, ML techniques and other methods like k-means classification can be easily trained in pre-operationalization processes but considerable computing power and memory might be needed in production.
Overcome the operationalization gap
British statistician George P. E. Box said: “all models are wrong, some of them are useful.” Since it is acknowledged that ML models cannot guarantee perfect and reliable results, how do businesses deal with uncertainties linked to that problem and what is their margin of tolerance towards forecasting efficiency. Knowing that it is not statistically possible to commit on a given accuracy threshold, we must decide what the acceptable issues of the operationalization of ML models are.
Beyond numerical gaps coming from the model outputs themselves, nobody can be shielded from unexpected events happening in the field that do not occur in a development lab environment. For example, extraordinary events such as the Coronavirus outbreak or Brexit are rarely detected before they actually occur. Their impact and variability can be huge, and drastically influence AI model efficiency.
In the second example of gas volume consumption forecasts, week, month, and year seasonality can be grasped and replicated, as well as holiday impacts and recent history trends. However, road works, weather hazards and outages are localized aspects that play a significant role in predictions, but even if they can be considered in model training, they cannot be considered on a real-time production platform, especially in long-term forecasts.
Solutions are multiple but not always easy to implement. Data quality alerting procedures and regular accuracy monitoring are essential to ensuring AI algorithm viability and stability. The need to have the best possible interoperability and compatibility in this Death Valley is crucial. Data scientists and IT have to collaborate in the AIOps universe to overcome the struggles of operationalization. Always keep in mind that every problem has its own solution; no answer means no existing problem!
